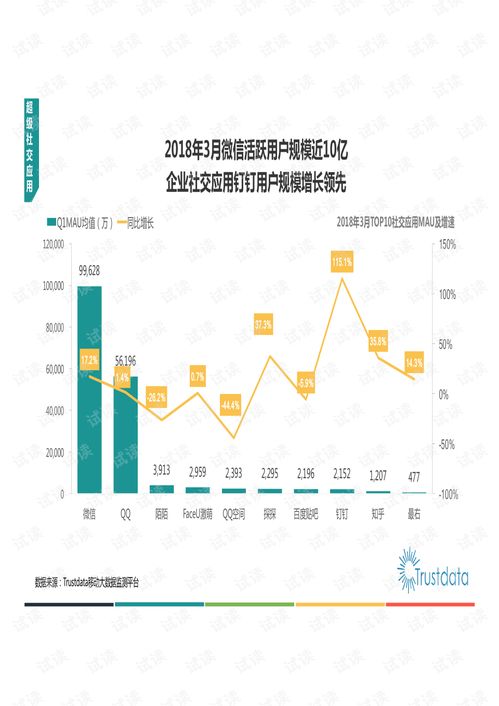
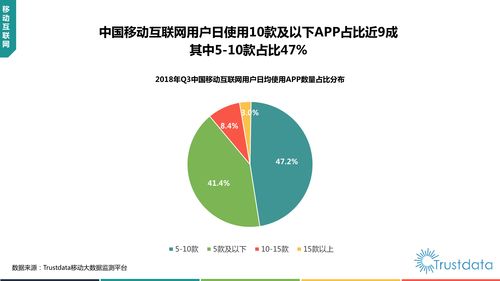
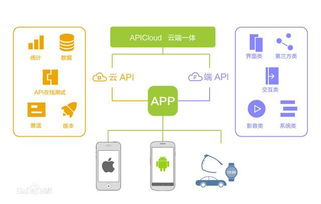
近年來,互聯(lián)網(wǎng)的快速發(fā)展深刻改變了社會生產(chǎn)與生活方式,尤其是在移動互聯(lián)網(wǎng)領(lǐng)域。本文基于相關(guān)資源(如CSDN文庫等平臺提供的行業(yè)報告和技術(shù)文檔),探討互聯(lián)網(wǎng)發(fā)展趨勢,重點關(guān)注移動互聯(lián)網(wǎng)的研發(fā)與維護。
互聯(lián)網(wǎng)整體呈現(xiàn)出智能化、個性化和去中心化的趨勢。人工智能和大數(shù)據(jù)技術(shù)的融合使得服務更精準高效,而5G網(wǎng)絡(luò)的普及進一步加速了物聯(lián)網(wǎng)和邊緣計算的應用。在這一背景下,移動互聯(lián)網(wǎng)作為核心分支,其研發(fā)重點轉(zhuǎn)向了高性能、低延遲和用戶體驗優(yōu)化。開發(fā)者需掌握跨平臺框架(如Flutter、React Native)和云原生技術(shù),以應對多樣化的設(shè)備需求。
移動互聯(lián)網(wǎng)的維護成為關(guān)鍵挑戰(zhàn)。隨著應用復雜性的增加,維護工作不僅涉及代碼更新和bug修復,還包括安全防護、性能監(jiān)控和用戶反饋處理。自動化運維(DevOps)和AIOps工具的引入,顯著提升了維護效率,減少了人為錯誤。同時,數(shù)據(jù)隱私和合規(guī)性要求日益嚴格,開發(fā)者必須遵循GDPR等法規(guī),確保用戶數(shù)據(jù)安全。
CSDN文庫等資源平臺為從業(yè)者提供了寶貴的知識和案例,促進了技術(shù)共享與創(chuàng)新。未來,移動互聯(lián)網(wǎng)將繼續(xù)向AR/VR、可穿戴設(shè)備等領(lǐng)域擴展,研發(fā)與維護的協(xié)同將推動行業(yè)可持續(xù)發(fā)展。把握趨勢、強化技術(shù)能力是應對互聯(lián)網(wǎng)變革的核心策略。